位置编码#
卷积具有局部性,天然地会注意元素之间的相对位置,但是基于自注意力的transformer模型则对位置不敏感,因此必须要把元素的位置信息在embedding阶段传给元素。 比如:
1我 爱 你
2你 爱 我在自注意力的理论中,这两个句子的表意是一样的,但是很明显这两者是天差地别的。
绝对位置编码#
在早期的BERT、GPT2等模型中,会直接将绝对位置编码加入到embedding中,但是绝对位置编码又分为两种
- 可学习的绝对位置编码:直接对不同位置随机初始化一个position embedding,将其加入到文本的embedding中,但是这样的方法引入了大量可学习的参数,需要大量数据才能训练。
- 固定绝对位置编码:attention is all you need中使用的三角位置编码
公式如下
$$ \begin{aligned} PE_{(pos,2i)}=\sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \\ PE_{(pos,2i+1)}=\cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}}) \end{aligned} $$其中$d_{model}$是位置编码的长度,$i \in [0,1,…,(d_{model}-1)/2]$。 采用这种设计,对于pos+k的位置的位置编码可以通过pos位置的位置编码线性表示得到。
相对位置编码#
是指将两个token的相对位置信息添加到对应的attention值中。
要对于相对距离远的进行惩罚。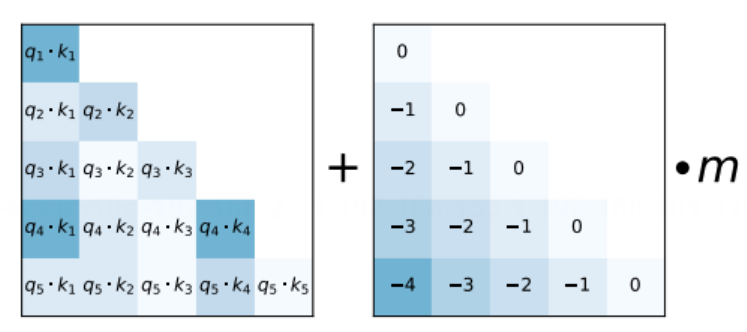
Attention with linear biases enables input length extrapolation(ALiBi)#
上图中就是ALiBi,传统的绝对位置编码会在训练时添加一个固定的向量,模型可能会过拟合这些特定长度的向量,于是ALiBi在分数计算的时候就添加了一个线性偏置,减少了模型对特定长度序列的依赖,提升了其对于未知长度序列的泛化性。
- ALiBi的位置偏差会随token距离线性增加。
- ALiBi鼓励模型关注更近的位置,但又不会完全排除远处的依赖。
XLNET#
T5#
DeBERTa#
旋转位置编码RePE#
RoPE实现了绝对位置编码和相对位置编码的统一,(通过绝对编码的形式实现了相对编码的效果)。RoPE最大意义就是在保留token位置信息的同时没有对token的语义产生污染。 RoPE将输入的序列位置信息通过旋转操作,嵌入到self-attention的计算中。 这个视频讲的很清楚,分别讲了为什么要用位置编码和RoPE如何推导。
旋转矩阵#
$$ \left\{ \begin{matrix} \cos \alpha & -\sin\alpha\\ \sin\alpha & \cos \alpha \end{matrix}\right\} $$上面这个公式就是一个旋转矩阵,他乘上$\left{ \begin{matrix} 0 \ 1\end{matrix} \right}$,就表明让这个向量在坐标轴沿逆时针旋转$\alpha$的角度。
对于p和q就分别乘上两个旋转矩阵,来表明其位置信息。
$$ \begin{align} Score=(q')^T \cdot k'&=(R(m\theta)\cdot q)^T \cdot R(n\theta)\cdot k \\ &=q^T \cdot R(m\theta)^T\cdot R(n\theta) \cdot k\\ &=q^T\cdot R((n-m)\theta)\cdot k \end{align} $$拓展到普遍情况#
上述是基于两维矩阵举的例子,实际情况中的token都是上千维,对于这种情况,RoPE采用了分治法。对于4096维度的矩阵,就给他拆成2048对。对于每一对都乘上旋转矩阵、添加位置信息。
问题#
旋转的话,10度和370度表示的意思就可能重叠,这样的话根本没办法表明独特的位置信息。为了解决这个问题,就可以利用刚刚上面的基本角度$\theta$,对于不同维度的矩阵,取用不一样大小的$\theta$,维度越低,$\theta$越大;反之,则越小。
因此就不需要担心重叠的问题,因为一个token的位置信息是由所有的旋转矩阵决定的,虽然低维度可能出现重叠,但是高维度还是能表明其独特性的。
准确说是很难重复,实际上也是可能重复的,但是重复周期会很长。
相对正余弦编码#
正余弦编码虽然也包含相对位置信息,如下
$$ \begin{align} Q &=W_q(X_m+P_m) \\ K&=W_k(X_n+P_n) \\ Score&=(X_m+P_m) (X_n+P_n)^T \end{align} $$注意力分数计算已经简化了。展开后如下
$$ \begin{align} Score &=(X_m+P_m)(X_n^T+P_n^T) \\ &=X_mX_n+P_mX_n^T+X_mP_n^T+P_mP_n^T \end{align} $$其中$X_mX_n$是有效语义信息,而$P_mP_n^T$是有效位置信息,其余都是无效信息(噪声)。RoPE则如下:
$$ \begin{align} Score&=QK^T\\ &=(R_mX_m)(R_nX_n)^T\\ &=X_mR_{n-m}X_n^T \end{align} $$很明显全是有效信息。 信息的有效性直接关系到模型的质量和训练成本(噪声大的模型需要更多的训练数据)。 这也就是RoPE能被广泛使用的原因。