transformer#
transformer是在这篇attention is all you need中提出来的。
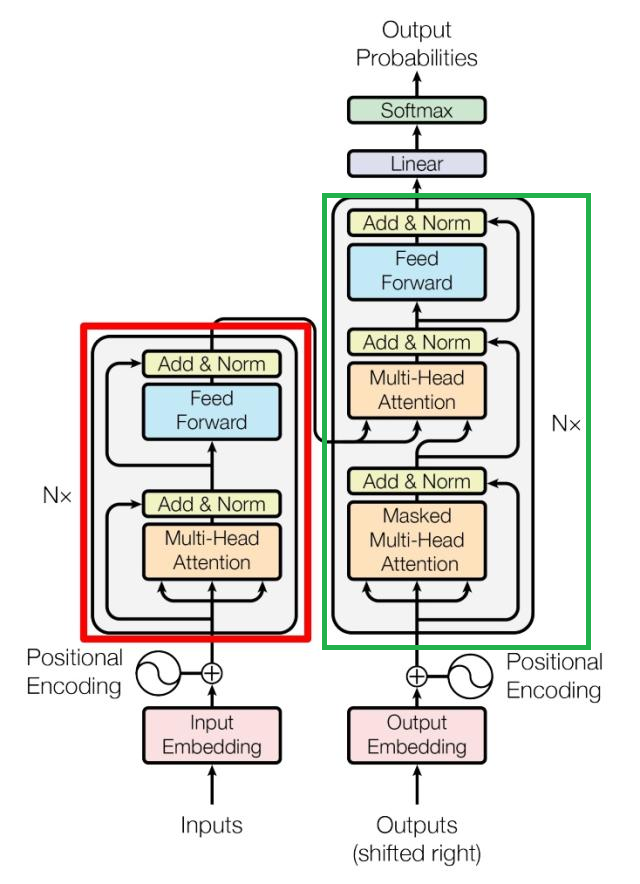
上图就是该论文最核心的模型架构图,本文也是围绕着这个架构图来展开的。
embedding#
由input embedding和位置编码相加得到,后面的文章详细介绍。
- input embedding可以通过word2Vec,bert,OpenAI Embedding API等方式获取,目的是将文本映射到连续的向量空间(把文本变成模型能处理的向量)。
- 位置编码是为了捕捉输入中token的顺序信息,常用的有rope,绝对位置编码等

encoder(编码器)#
图片中的红色框内,就是encoder。
 可以看到encoder是有N个`multi-head attention`+`add&norm`+`feed forward`+`add&norm` 组成的。`multi-head attention`是多头注意力机制,在这个文章中有详细介绍。[self-attention](https://affine.somnus.top/workspace/09e2838e-0333-4d5c-80d5-bcae278e8e50/qQsakBqRrL2JR41Rk7p2h),`add&norm`是两个步骤,add是指把源数据和经过运算输出的数据叠加起来,norm则是对其进行归一化操作。公式如下:
$$
LayerNormalization(X+Multi-Head Attention(X))
$$
可以看到encoder是有N个`multi-head attention`+`add&norm`+`feed forward`+`add&norm` 组成的。`multi-head attention`是多头注意力机制,在这个文章中有详细介绍。[self-attention](https://affine.somnus.top/workspace/09e2838e-0333-4d5c-80d5-bcae278e8e50/qQsakBqRrL2JR41Rk7p2h),`add&norm`是两个步骤,add是指把源数据和经过运算输出的数据叠加起来,norm则是对其进行归一化操作。公式如下:
$$
LayerNormalization(X+Multi-Head Attention(X))
$$此处公式中用的是LayerNormalization,而对于norm的位置,也分成了pre-norm和post-norm,分别是指norm的操作在残差连接之前和之后。上图中就是post-norm。
feed forward即两个简单的全连接层。公式如下:
Attention 负责** token 之间的信息交互**,让每个 token 根据上下文更新自己的表示;**FFN 负责对每个 token 各自做非线性变换**,提升表达能力。FFN 虽然看起来只是两层全连接,但它通常占 Transformer 参数量很大,不是“简单附属模块”。
decoder(解码器)#

可以看出来decoder相对于encoder是要复杂一点的,除了一个N次处理循环block以外,最后还有线形变换和softmax处理。
在循环处理的block中也有不同,我们可以看到第一个多头注意力增加了一个masked,表明这个注意力机制有一个掩码矩阵。为什么要有掩码矩阵可以看self- attention这篇文章self-attention。上图中的第二个多头注意力机制是cross-attention,是指decoder层用来看encoder输出的注意力层。对于decoder-only是没有这个cross-attention的。
最后还有一个softmax,根据前面的知识,在self-attention的模块中是存在softmax,而这两个softmax很明显负责的功能是不一样的。其中self-atttention中的softmax是用来告诉当前的位置应该关注哪些位置,而这里的softmax是表明下一个token应该表示词表里的哪个词。
only模块#
encoder-only#
常见的模型是:BERT,RoBERTa。
它通常是双向注意力机制,即不需要要掩码,可以看见未来token。
侧重于理解,所以它很适合理解完整输入,比如:
- 文本分类
- 情感分析
- 句子匹配
decoder-only#
常见模型是:GPT,Mistral,LLaMa。
它使用的是单向注意力机制,需要给未来token添加掩码,不可以可以看见未来token。
侧重于生成,所以它天然适合生成:
- 聊天
- 写作
- 代码生成
值得注意的一点是,现代的decoder-only大模型也可以作为理解任务,因为在模型训练的时候会投喂很多理解型的数据,因此很多的理解任务都被转成了生成任务。
Decoder-only 模型通过预测下一个 token 学到了上下文表示;在回答时完整输入都位于它左侧,所以它能读完整问题,再把理解任务转化为生成答案。它不是像 BERT 那样双向编码全文,但足够大、数据足够多、训练方式足够好时,生成过程本身就承载了理解。
解码策略#
在自然语言生成的任务中,我们通常使用一个预先训练好的大模型来根据我们的输入生成输出文本,而大模型给的输出是下一个token的概率分布,而如何在这些概率分布中选择,便是解码策略。
目前主流的解码策略有以下几种:
- 贪心解码:即直接选择最大概率的token
- 随机采样:按照概率分布随机选择一个单词
- beam search:维护一个大小为 k 的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k 个单词,然后保留总概率最高的 k 个候选序列。
以上的方法各有各的问题,而top-k和top-p采样就是介于贪心和随机采样之间的策略,也是目前大模型最常用的解码策略。
top-k采样#
为什么不能直接用贪心解码,想象我们智能手机的输入法推荐下一个字,他就是贪心解码策略,直接给你按照从高到低概率排列,但是如果我们一直按第一个,会发现句子逐渐越来越重复。而top-k就是从概率最高的k个单词中,采用随机采样来选一个单词。
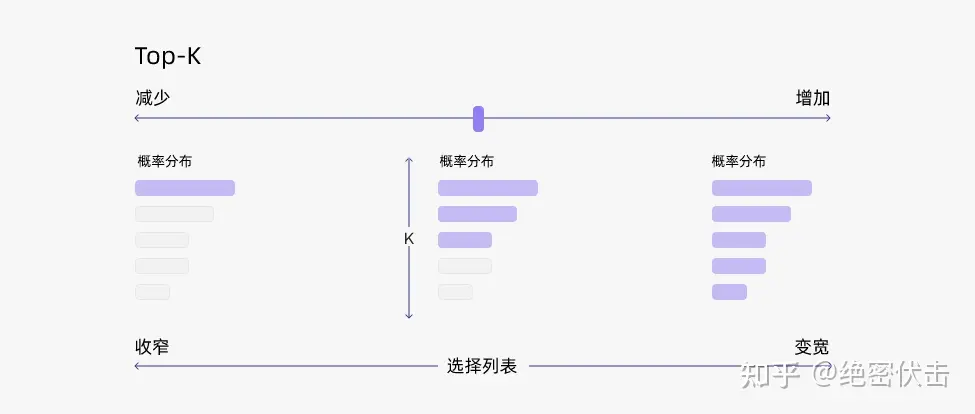
上图中,紫色部分便是被选中的,可能被选择的词。
Top-k 的优势是简单、稳定、能过滤低概率噪声,相对更多样;劣势是固定 k 太机械,容易在模型很确定时放得太宽、在模型不确定时收得太窄。
top-p采样#
top-k有个很明显的问题,就是这个k如何确定,如何选择才更合理,于是出现了动态设置 token 候选列表大小策略——即核采样(Nucleus Sampling)。
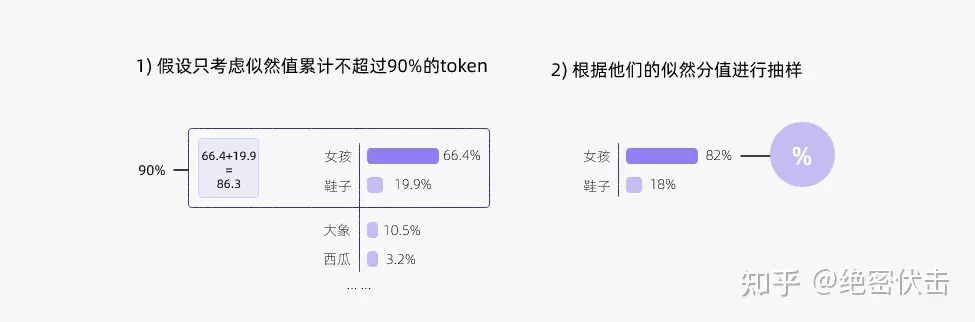
由上图中可以看出来,top-p的策略是设定一个p,只保留从高到低累计概率小于p的token,这样就可以避免上面top-k的一些问题。
Top-p 的优点是自适应、灵活、能过滤长尾,特别适合开放式生成;缺点是 p 需要调,分布平坦时候选可能过多,而且随机采样仍可能带来不稳定。
在现代的大模型中,top-k和top-p往往都是同时采用的。即先进行top-k采样缩小候选范围,再在这个候选范围中采用top-p采样来保留高概率的候选集合。
同时启用 top-k 和 top-p,是为了让 top-k 提供候选数量上限,让 top-p 根据概率分布动态收缩候选集合;两者结合能减少低质量长尾,又避免固定 k 过于机械。
temperature采样#
temperature采样的本质就是先对logits做一些缩放,再进行softmax。
$$ p_i = \frac {exp(z_i / T)}{\sum_j exp(z_j / T) } $$$z_i$ = 第 i 个 token 的 logit,T = temperature,$p_i$ = 第 i 个 token 的采样概率
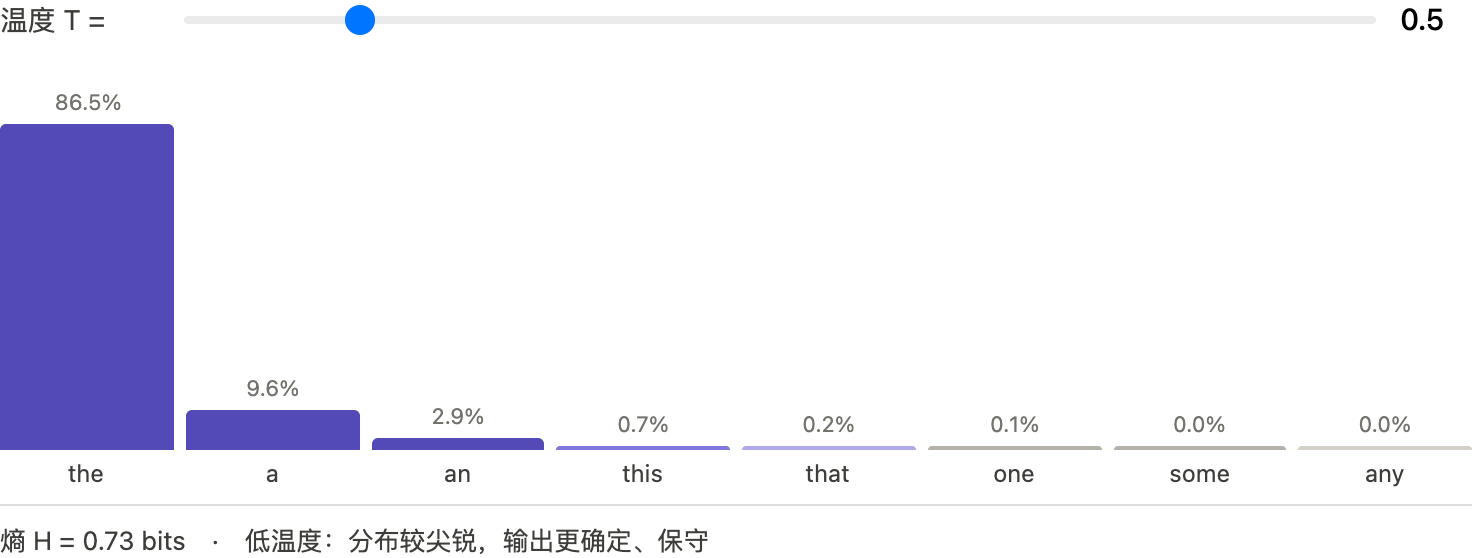
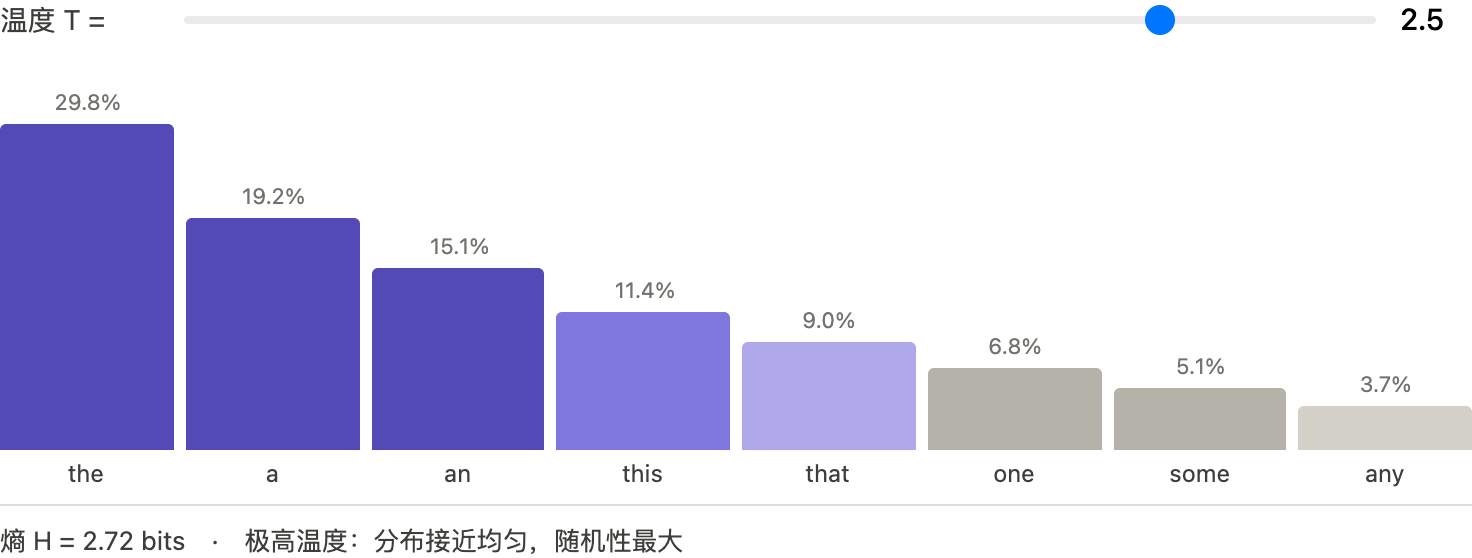
结论就是,温度越高随机性越大,分布越均匀,越发散;温度越低,随机性越低,分布更尖锐,越保守。
联合采样(top-k & top-p & Temperature)#
通常我们是将 top-k、top-p、Temperature 联合起来使用。使用的先后顺序是 top-k->top-p->Temperature。
我们还是以前面的例子为例。
首先我们设置 top-k = 3,表示保留概率最高的3个 token。这样就会保留女孩、鞋子、大象这3个 token。
- 女孩:0.664
- 鞋子:0.199
- 大象:0.105
接下来,我们可以使用 top-p 的方法,保留概率的累计和达到 0.8 的单词,也就是选取女孩和鞋子这两个 token。接着我们使用 Temperature = 0.7 进行归一化,变成:
- 女孩:0.660
- 鞋子:0.340
接着,我们可以从上述分布中进行随机采样,选取一个单词作为最终的生成结果。
Q&A#
Q1:Transformer block 里 attention 和 FFN 分别负责什么?
A1:attention是主要的模块,是用来训练模型能关注更重要的信息,而FNN是两个简单的全连接层。
Q2:Encoder 和 Decoder 最大区别是什么?
A2:我认为最大的区别是encoder的输出可以输入到decoder中,decoder因此具有cross-attention功能,除此以外,还有一些区别,比如encoder的注意力是不需要掩码的。
Q3:为什么 GPT 用 Decoder-only 架构?
A3:GPT是generative pretrain transformer特指生成式的大模型,而decoder天生就更适合生成式的任务,因为他的单向注意力机制等等特性。
Q4:logits、softmax、probability 三者是什么关系?
A4:logits 是“还没正规化的偏好分数”;softmax 是“归一化成概率分布”;probability 是“最终每个 token 的概率”。
Q5:temperature 变大/变小分别会怎样?
A5:温度越高随机性越大,分布越均匀,越发散;温度越低,随机性越低,分布更尖锐,越保守。
Q6:top-k 和 top-p 的区别是什么?
A6:top-k是指定k个候选项,按照概率从高到低选择,而top-p是指定累计概率p,按照概率额从高到低选择累计概率小于p的候选。
整体过了,尤其 Q4/Q5 很稳。帮你把几个点修准一点:
Q1 需要补上关键分工:Attention 负责 token 之间的信息交互,让每个 token 根据上下文更新自己的表示;FFN 负责对每个 token 各自做非线性变换,提升表达能力。FFN 虽然看起来只是两层全连接,但它通常占 Transformer 参数量很大,不是“简单附属模块”。
Q2 你的理解基本对,但“最大区别”可以更直接:Encoder 是双向理解,Decoder 是因果生成。在原始 Encoder-Decoder Transformer 里,Decoder 还有 cross-attention 去读 Encoder 输出;但 GPT 这种 decoder-only 没有 encoder,所以也没有 cross-attention。
Q3 对。更完整说法:GPT 用 decoder-only 是因为预训练目标是 next-token prediction,天然要求当前位置只能依赖历史 token。Decoder-only 结构简单、训练目标和推理方式一致,很适合规模化生成。
Q6 小修:top-k 不是“按照概率从高到低选择”,而是只保留概率最高的 k 个 token,然后在这 k 个里面重新归一化并采样。top-p 是保留从高到低累计概率达到 p 的最小候选集合,然后重新归一化并采样。你说的“小于 p”接近,但通常是“直到累计概率达到/超过 p”。